[Video & Notes] State of the Browser 5 - Animation Performance
This talk was initially based upon the talk I gave at the Extensible Web Summit but I have expanded it to encompass animation performance in general.
This page will ask for microphone access for a demo further down the page. (spoiler!!)
Slides: https://gh.ada.is/animation-performance-slides/
Other talks from State of the Browser 5, by some truly excellent speakers London Web Standards Channel
The talk notes,
These are my original notes, I left out many points during my actual talk and I think I may have about 40mins worth of content here but I think I managed to get the gist of it out on the day.
I have annotated my slide notes with pictures and reformated them back into paragraphs.
Notes:
- Self plagiarism note: The beginning of this talk is evolved from a previous talk & blog post.
- Some of the words/phrases are spelt or punctuated incorrectly. This is to help me with pronounciation. e.g. parsing/parzing.
Introductions
Hi, I’m Ada Rose from FTLabs,
Aim to cover rendering and animation performance. Both in the DOM and also general 2D and 3D animation in the web. I will touch on many different things and hope to provide some inspiration.
The ideal feeling is that of a native experience. The goal of good performance is so that the user doesn’t notice they are in a web page.
- Make sure user interactions such as scrolling/dragging is responsive
- From the moment the content is visible
- Manage user expectations, don’t show what they cannot interact with
- Usually this means taking time to calculate an animation before rendering it
- If you can move as much as possible out of the main thread, into workers or onto the graphics card.
I’ll begin with rendering in the DOM then move onto some practices which help for animated visuals.
Jank
The user shouldn’t feel their very expensive device is struggling to display a simple a web page. So we have a goal framerate of 60fps, which gives us 16ms to render a single frame.
When the frame takes longer to layout and render than 16ms that is jank. It looks like a stuttery discontinuity in the animation. Jank shows up in the timeline as very tall bars:
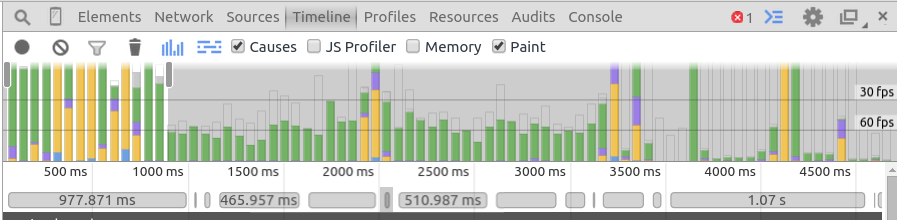
It’s been shown that 60fps with occasional hiccoups feels much slower than a continuous 30fps but the browser will always attempt 60fps even on higher refresh rate screens as far as I am aware.
Long frames are caused by too much blocking activity in the main thread. This can be an intense cpu bound operation or blocking IO (localstorage, sync ajax). However most commonly on a typical webpage slowness is caused by the layouts and paints used to render the page.
A very very simple view of the render pipeline is:
- Measure Element’s position and size in the Layout step.
- Certain elements are rendered into bitmaps in memory in the paint step
- The graphics card then draws these bitmaps to the screen in the composite step
Layout is slowest. 🐢
- Layout - browser calculates the positions and sizes of all the elements in the page.
- Making a small DOM change could potentially invalidate the entire DOM tree
- An invalidated DOM is recalculated when each frame is rendered.
- it is also recalculated whenver layout properties are read
- So layout may be recalculated many times in a single frame.
An element needs to be repainted when it’s appearance changes such as font-family or background colour. If an element’s layout changes its also needs to be repainted.
🐰 Composite is very fast. Composite only involves the graphics card rerendering from bitmaps calculated in paint and stored in memory: it is performed when the page is being drawn to the screen. It is triggered by gfx card-only operations such as transform, clipping and opacity.
CSS triggers is a great resource for discovering how properties trigger each of these operations.

One should try to touch layout properties rarely but can be pretty free and fun with animating compositing properties.
DOM
Writing to layout properties is free; you can write as much as you want. It’ll only be recalculated on render or when one of its layout properties is read. (scaleHeight, getBoundingRect())
One common problem is reading, then writing in a loop, which is known as layout thrashing;
The layout is invalidated and recalculated on every single read. Interleaving reads and writes could mean multiple expensive layout operations per frame.
One fix for DOM thrashing tends to be fairly simple: batch your reads and writes all together. Especially don’t change a property then immediately read it.
For example don’t append to innerhtml in a loop INSTEAD build up a string and then write that string to the innerhtml.
In an mvc or a large framework with many independent modules it can be difficult to ensure modules do not interleave read and writes. Wilson Page’s fastdom library can help with this so that reads and writes in a single frame all get done together.
Frame Source
- Dom thrashing by Measure/Write loop
- Dom thrashing by appending to DOM
- Screenshot of github
- How fastdom reorders your functions
- Relayout on Every Frame due to CSS animation. May make device warm.
- A paragraph of text.
It does this by allowing you to add your read and write callback functions to seperate queues these queues are flushed once per frame. So that it performs all the reads then all of the writes. Thus giving you an async api to turn interleaved read and writes into queue of layout reads then layout writes.
Sometimes one wants to animate an element growing or sliding in. Naively one might put a transition on an elements height or left css properties. Animating properties like these which effect layout will trigger a relayout on every frame.
Although it [the slide with the bouncing layout] doesn’t look like much (and is probably rendering pretty smooth) it is making my fan spin up and get’s my phone really hot, working on these slides really runs down my battery. With more content or images this would be Janky too!
In that particular example I am animating the ‘width’ property of only a few elements. This is one of the properties which triggers layout. It is being changed and so requires a re-layout every single frame by the css animation.
A good general motto is to calculate all DOM changes first then apply them in a single step.
One can then animate that single step by animating the transforms of the elements. In the example where I position the white/blue boxes to show the un-interleaving of functions in fastdom I make good use of this. https://github.com/AdaRoseCannon/a-slides/blob/perftalk/app/_scripts/content/dom.js#L49
In a single frame I do the following:
- First I create and layout the elements in their initial position.
- I measure their positions and sizes
- I perform the function which repositions them
- I measure their new position
- I persform the transform which returns them to their original position.
I can then wait for user input (the
yieldstatement);
I add a transition & reset the transforms
The elements slide smoothly move into place without needing a single DOM interaction
So the reaction is instantaeneous and Jank free.
But why is layout so hard on the browser?
Changing a single element could have an effect on every single other element on the page.
Every touched element also to be repainted.
Typeface slide
Another reason is the rendering of typefaces. Type is so ubiquitous about the web it is very easily to take it for granted but it is very difficult to render especially when you appreciate that every character needs to be kerned and hinted, every word and paragraph needs to be placed and flowed correctly.
Composite slide (The one with the circling faces)
Compositing is great. Transforms such as Rotating or scaling are all done off the main thread. They are performed on your phone/desktop’s graphics chip. Graphics chips are very good at applying transforms. The transforms on a single webpage are nothing compared to a modern computer game.
Layout Boundaries and Containment
Even though this modal looks isolated…
the browser may still relayout the whole Dom as it’s content changes.
However, we can seperate its layout invalidation from the rest of the page. Doing so doesn’t accelerate the animation, but it does make the layout change less catastophic.
There is a draft css spec called containment which provides a hint to the browser that this element will not affect the rest of the DOM tree.
The containment spec requires certain properties, such as no scrolling and fixed dimensions.
{
height: <fixed value>;
width: <fixed value or a %>;
overflow: hidden;
position: absolute;
contain: strict; // In draft
}
Containment can be done in browsers currently. But it relies on undocumented browser behaviour. It requires the element to have certain properties before it can be optimised,
- position absolute
- fixed height
- no scroll
and is entirely dependent upon the browser’s implementation.
The containment property would be really good because it makes explicit as a performance enhancement
what was previously only doable by setting a variety of properties.
The performance gains from these could not be relied upon in every browser and using styling hacks for performance feels messy.
Containment will enforce certain styling neccessary for the isolation. Which means it could potentially cause an element to be styled differently to how the user expects. E.g. no scrolling.
#Note Layout Containment is not the same as style containment as defined in the web components spec.
Style containment stops custom elements styling affecting other elements;
containis for layout containment it is a css property in draft. It is to aid performance by allowing the browser to isolate certain elements from the rest of the DOM’s layout tree.
Removing work from the main thread.
The Web for many years was single threaded. Now we have web workers they allow us to offload some work into additional threads on the cpu. So we can leave the main thread to focus on performing the rendering operations.
- JSON parzing is slow.
- We can use web workers (or the Service Worker) to perform our ajax requests and parze the JSON off of the main thread.
- We can then query bits of the JSON through the postMessage or MessageChannel apis.
We can also use workers to do complex calculations which do not rely on interacting with the DOM.
Compression library to expand data recieved in an ajax request. This data can then be processed in the worker and queried from the main thread.
On the lighter side; If your website’s winter holiday theme has realtime physically correct snowfall then perhaps perform these calculations in a worker and transfer the positions/rotations of each snowflake back to the main thread for rendering.
But beware, there is a hidden cost of using workers. Transferring the data back to the main thread is not free. It needs to be deserialised in the main thread. So if you download a JSON file and parze it in a worker then send the whole object back to the main thread you gain NOTHING. The main thread still has to deserialize back into a JavaScript object.
So make sure you only send what you need for rendering back to the main thread.
Message Channel API
https://googlechrome.github.io/samples/service-worker/post-message/
Interfacing with workers is usually quite a bellyache with the postMessage API.
The MessageChannel API which recently gained support across all platforms. Allows us to create a nice pattern for sending messages to workers.
workerMessage({
action: 'doThing',
myVar: 4
})
.then(data => {
console.log(data.response);
});
This is the important bit, the interface once can make is very simple and promise based much like the fetch API. Greatly increasing the ease of working with workers.
LocalStorage - A Synchronous IO
Of the older webapis which are synchronous LocalStorage is probably the most commonly still used.
There are several situations where it can be slow.
My recent tests in Cr45 for mobile and desktop show that it’s is about 1/3 the speed of writing to memory.
So really not too bad. If speed is essential it still may be best to use an async storage method such as IndexedDB. Unlike local storage IndexedDB can also be used in workers.
Trading precaching for performance
On the a page’s first load it is pretty common practice to cache a whole bunch of assets for later use. Front loading your content like this can be great for later loading performance. Unfortunately parzing JS and decoding images can also quite expensive.
This added stress can make your site’s first few moments be really janky or even unresponsive. The user can neither click nor scroll. You might as well have just sent down a pretty picture of your above the fold content.
When the page looks like it is ready to be used it should also be readily responding to a users interactions.
Especially if a site has an interstitial.
The user’s very first interaction with your site, they are presented with
A barrier requiring the user to interact in order to see sone content.
Since the browser is struggling with parzing and caching the new assets.
The user’s attempts to close the interstial are futile or laggy,
they will probably bounce rather than wait for the site to start working
If an interstitial looks closable but isn’t responding straight away this is not a good experience
Load just the minimum amount of content for the first use. Load more later into the site’s life time. If there is need to query some large JSON to view your site but not all the data is needed right there and then.
Don’t try to eat an elephant in a single mouthful.
If you are using a Service Worker you are probably already doing precaching off thread using the cache API so good on you.
On our Six Degrees of Angela Merkel Four oh Four page project I start with just 20s worth of precalculated data for our animation to get started fast.
The remaining 10MB of data was also broken into 20s chunks which could be parzed in a single frame.
Parzing a full 10MB JSON file would have caused our smooth animation to look Janky during the first few seconds when we have the most of the user’s attention.
You can compromise on performance though,
The times when the site needs to be most responsive is when interaction and animation is happening e.g. the user is touching, dragging, swiping or scrolling or when the user is being prompted for input.
But there are a few situations where you can be slow without the user noticing for example just after a click or tap interaction it takes about 100ms unresponsiveness for a site to start to feel slow. Which is oodles of time to perform a large calculation such as precaching data or performing calculations for an upcoming animation.
[If you are reading my notes check the code for the fastdom slide as mentioned above]
If you are careful and nothing is being animated for example the user is reading an article take this time to deserialise a json object or precache the user’s potential actions.
WebGL Shaders
In WebGL to produce special effects really performantly shaders can be used. Shaders are scripts which get compiled when instantiated (this can be slow). They can process huge amounts of data very quickly on your computers graphics card. This has the advantage of being off the main thread and being run on your computers graphics hardware.
Graphics cards are very powerful and specialise in vector maths can process huge amounts of data very quickly. They can process many thousands of points in a few milliseconds. If working with WebGL and are animating a fixed topology e.g. 3D graphs and data visualisations, fixed geometry models. Tranform each point in the Shader rather than setting the geometry using the cpu, you will get very good performance.
In this demo I send sound data from the microphone to the Shader. The shader then processes this data to work out how it should effect each point on the model. There are over 4000 vertices and it does not struggle even on a lower end phone.
In my early prototype I used the cpu for this. It got very hot and this is a google cardboard demo. I thought it was important avoid setting fire to the cardboard headset with the mobile’s cpu. (Joke)
That’s not the kind of face meltingly awesome VR one should strive for.
Super crazy (don’t do this),
If you would like to process HUGE datasets with 100s of thousands of data points.
Your complex operation one can code your complex operation into a shader.
Then the data can be entered in much like I did with the bunny demo.
But instead of rendering an awesome demo.
One can draw the values out as pixels in a framebuffer.
You can look at the colour of each pixel to extract your data from Red Blue Green information.
Allowing you to use the power of your graphics card for data processing.
Kind of like NVIDIA CUDA or OpenCL.
But seriously don’t do this. (But if you do send me a link I want to see it.)
SIMD
On the more realistic side of things there is an upcoming API which will allow you to do parallel data processing on the cpu in the web.
It is called SIMD.
It will allow one to perform simultaeneous calculations by mapping four numbers as dimensions of a 4 vector and do 4 operations at once.
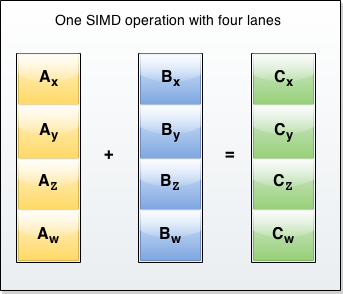
In a way very similar to the way shaders do on the graphics chip.
It is still on the cpu but should be able to process a large dataset much faster.
A factor of 4, 8 or 16 faster depending on the size of the vector used.
It can be used now in firefox nightly and in wrapped webapps by shipping, Chrome which has SIMD compiled in, Intel XDK can do this for you.
Or you can just wait a bit for it to enter the mainstream browsers.
Conclusion, Make it feel fast,
- Make sure scrolling/dragging is responsive
- Make it behave from the moment the page is loaded.
- Manage user expectations, don’t show what they cannot interact with
- Measure everything first then render second
- Move as much as possible out of the main thread, into workers or onto the graphics card.
-
- but beware of serialization costs of transferring data between threads.
References
- http://dev.w3.org/csswg/css-containment/ - Containment Spec
- Fastdom - Library to avoid read/write loop
- http://csstriggers.com/ - CSS Triggers
- https://css-tricks.com/things-chrome-dev-summit-2014/ - Great Paul Lewis talk
- https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/SIMD - MDN SIMD
- https://www.flickr.com/photos/sndrv/16276901852 - Man wearing cardboard