Making a useful ‘offline’ page for your web app.
We can’t guarantee our users have a good internet connection but we can still be helpful when they don’t.
In ideal conditions the user will always maintain a good connection to the web but things are seldom ideal. Fortunately since we’re been building a web app we have a service worker which has the capability of caching network responses.
If the network fails or takes too long to respond we can then use these cached responses to show the user the page they were looking for, letting people continue to use the app despite not being connected. Unfortunately our cache isn’t always perfect. Sometimes the user will be trying to go to a page which hasn’t been cached yet.
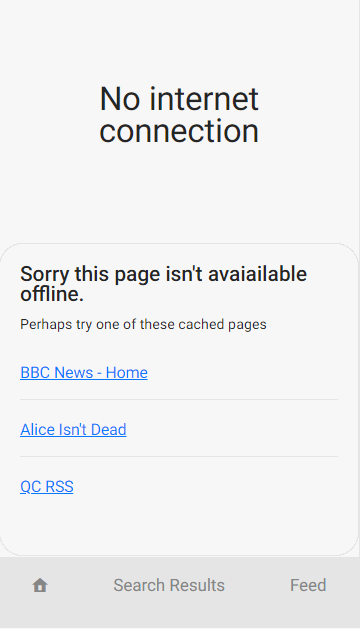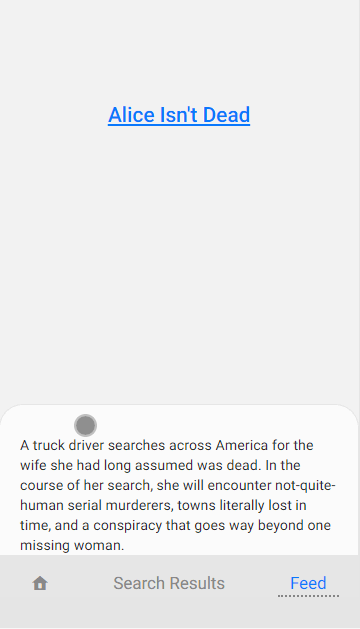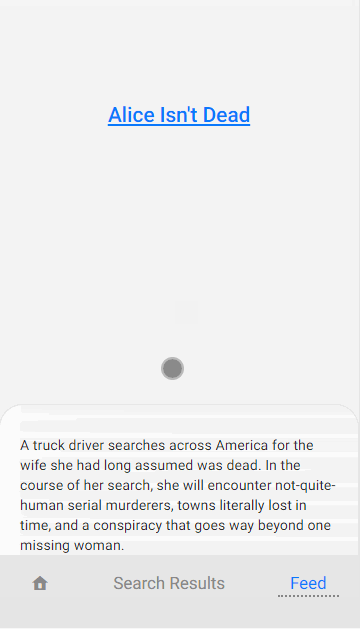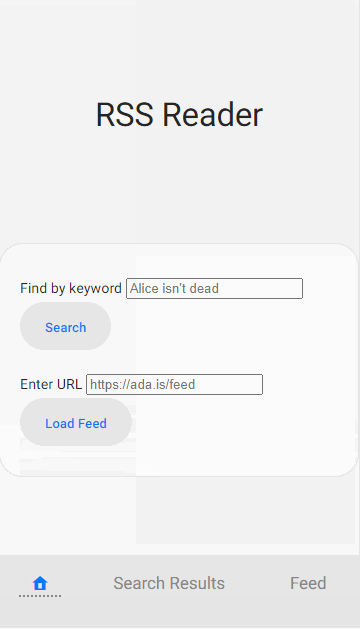
If we haven’t anticipated this we may see the dreaded no connection message:
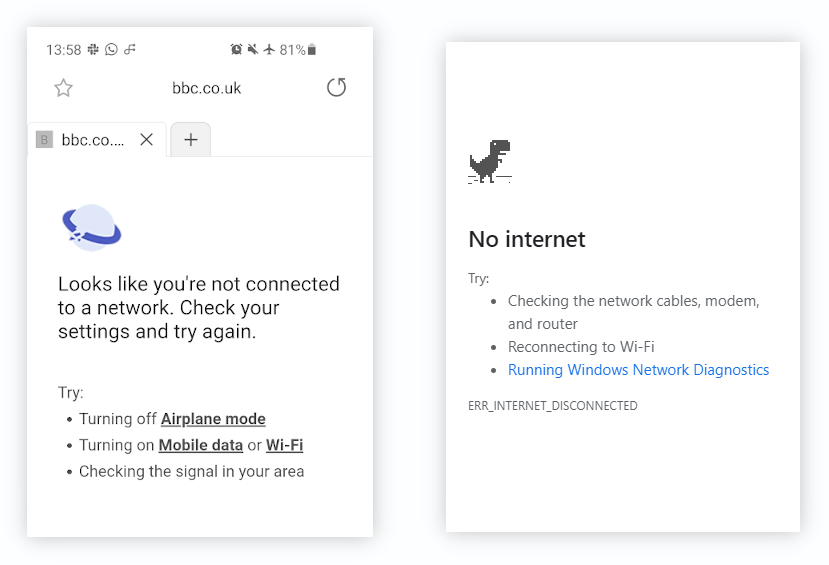
Fortunately we are very smart developers [citation needed] and can show a branded offline page. So the user still feels like they are using our web app when the connection is lost. here are some examples:
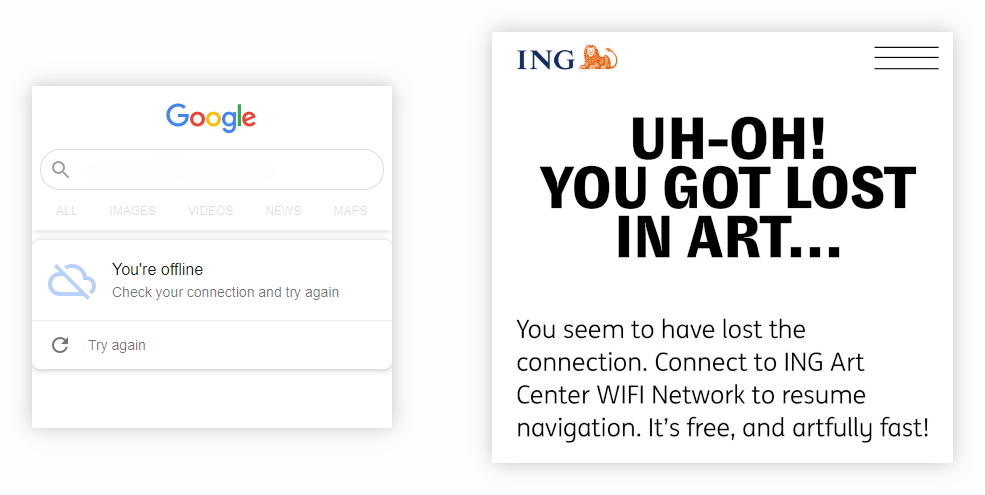
These are great for maintaining a consistent user experience during network failures which is the expected behaviour of a native app.
These pages can do even more though, they can be used to provide entertainment such as The Guardian’s developer blog providing a crossword on their offline page. Which unfortunately I can’t find a live version of any more.
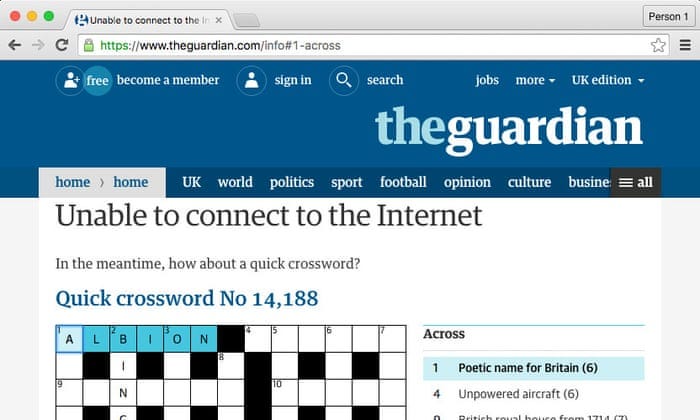 The Guardian’s crossword offline page.
The Guardian’s crossword offline page.
A useful offline page for almost any Web App
I’m going to propose, and build, a feature which should be useful to many apps and websites and would make your app still partly usable whilst your offline. This is to show a lit of relevant cached pages to the user:
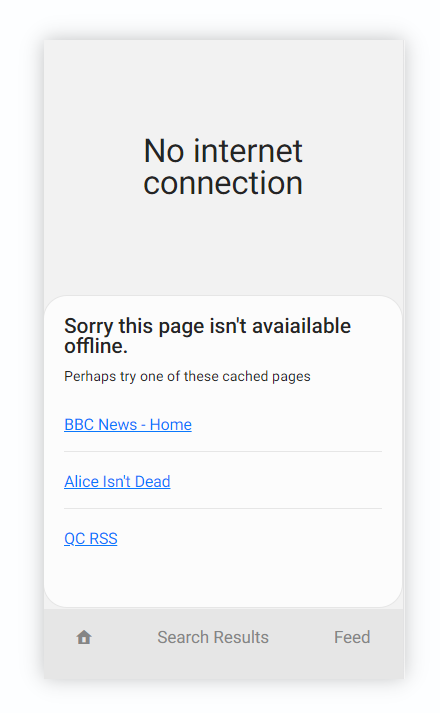
This example app is an RSS Feed reader. Where the user can read an RSS feed at a URL like so:
/feed/?url=https://ada.is/feed
This app is rendered on the server so it returns all the information in the HTML page, these pages get cached by the service worker. If your app uses JSON to populate pages on the client side this technique still works as long as you cache both the JSON responses and the pages which show them.
This is a common pattern in many Web Apps and will work as long as you have pages cached.
Step 1. Be prepared, by pre-caching the offline page
Firstly we need to store the offline page, when the app starts. To do this I had the HTML file /offline/ and it’s resources /offline.js cached as soon as the app starts, by populating the cache during the service worker’s install event.
const CACHE_NAME = "DENORSS-v1.0.0";
self.addEventListener("install", (event) => {
event.waitUntil(
caches
.open(CACHE_NAME)
.then((cache) =>
cache.addAll(["/", "/offline/", "/offline.js"])
)
.then(self.skipWaiting())
);
});
Step 2. Show the offline page
Then when the user tries to navigate to a page we do not have we can show that cached /offline/ page.
Our existing code first tried to respond with a live page, if that failed it would try retrieving the page from cache, if that fails instead of just failing and showing the browser error message we instead respond with the offline page.
// Try showing the offline page if it's a navigation
if (event.request.mode === "navigate") {
const offlinePage = await caches.match("/offline/");
if (offlinePage) return offlinePage;
}
Step 3. Getting a list of cached pages
This now shows the offline page when there is no alternative. Now lets provide a list of cached pages the user might like to read instead. Like in the example below.
The first step we need to do is to open the web apps caches to find pages we want to access:
const cacheKeys = await window.caches.keys();
const caches = await Promise.all(
cacheKeys.map((cacheName) => window.caches.open(cacheName))
);
This gives us an array of caches.
Next we want to find all of the cached pages from those caches, this works by using cache.matchAll with ignoreSearch: true to find all cache results from the /feed/ endpoint.
const results = await Promise.all(
caches.map((cache) =>
cache.matchAll("/feed/", {
ignoreSearch: true,
})
)
);
I only looked at the /feed/ end point because I felt that pages like /search/ with search results or the error pages like /404.html would not be useful to users and main pages like the home page / are already linked to in the navigation bar.
Our results returns an array of arrays for the results from each cache. We will flatten this and then handle each cached response:
results.flat().forEach(async (response) => {
// Code goes here
});
We only want to get the useful pages to the users so we will look at the query parameters to find only the pages are interesting. For our example they are requesting an RSS feed via the url parameter.
const params = new URLSearchParams(new URL(response.url).search);
const urlParam = params.get('url');
if (!urlParam) return;
If there is no url query parameter, it’s not interesting so we won’t show it.
Step 4. Rendering the list
We have the URLs of the pages now and the raw query parameters but that won’t look very good for users. We can get some better labels to show to users by looking at the cached content itself.
To get the data out of the response we need to get the text of the response:
const dataAsString = await response.text();
If your data is stored as JSON then a JSON.parse should be enough to retrieve any interesting information such as a good page title.
const data = JSON.parse(dataAsString);
const title = data.title;
For our example website, since it is server side rendered it uses HTML so I will parse the HTML instead, fortunately web browsers are good at HTML parsing. We will turn our raw text into a document fragment which can be queried using the usual DOM methods.
In this example we read the text in the
const html = document
.createRange()
.createContextualFragment(dataAsString);
const title = html
.querySelector("title")
.textContent.trim();
We use this title and the response URL to generate a link we can append to the list element to make a list of pages.
el.insertAdjacentHTML(
"beforeend",
`<li><a href="${response.url}">${title}</a></li>`
);
Here is a gif of it working, this was recorded with Chrome emulating an offline network connection:
Thanks for reading and hope this helps.
By Ada Rose Cannon on July 27, 2020.